什么是心流体验呢?它是一种复杂、多维的反射性心理结构,其特征是人们在具有挑战性的活动中保持愉悦的专注状态(Csikszentmihalyi,1990)。当学生在学习活动中处于心流状态时,他会觉得与学习相关的行为几乎都是自发的、有意义的。如果教师可以在在线学习过程中获得有关学生心流水平的反馈,他们就能更轻松地了解学生的在线学习状态并设计出更好的学习材料和教学方法。
这是来自浙江理工大学理学院心理学系刘宏艳教师团队的一项科学发现发表于2023年2月的国际人机交互杂志(International Journal of Human-Computer Interaction),它报道了采用多模态学习分析识别学生在线视频学习时的流体验。

(图片来源:网图)
那么如何才能识别学生在线视频学习时的流体验呢?多模态学习分析(MMLA)提供了一种识别学生学习状态的有效方法(Oviatt et al., 2018),它通常收集有关学习者的同步多流数据,如行为(语音、眼动、姿态、面部表情)、生理(心率、皮肤电、呼吸)和神经(脑电)特征,并利用各种 AI 方法(如机器学习/深度学习算法和数据挖掘技术等),旨在发现以学习为导向的新现象,推进学习理论,为理解学生的学习方式提供新的方法或标准(Blikstein & Worsley, 2016; Crescenzi-Lanna, 2020; Di Mitri et al., 2018; Worsley et al., 2021)。
本研究根据流理论四渠道模型为视频学习设置了一个教学场景,以促发学生的无聊感、心流和焦虑感。我们基于四种模态信号(生理、姿势、面部表情和语音)来识别学生的学习状态并预测学生的心流体验分数。我们假设,融合所有数据源的这些特征可以显著提高三种学习状态的识别准确率和流体验的预测能力。
32名在校学生参加了实验。通过预实验筛选出来自大学MOOC网的3个视频。在无聊条件下,视频内容是欣赏一首名为《江雪》的古诗,时长8分35秒;流状态下的视频讲述的是马格努斯效应,时长8分35秒;焦虑条件下视频讲述了机器学习支持向量机原理,时长9分55秒。流状态和焦虑状态下的视频插入了4道单项选择题,学生需要作答并能获得反馈。视频的学习界面见图1。
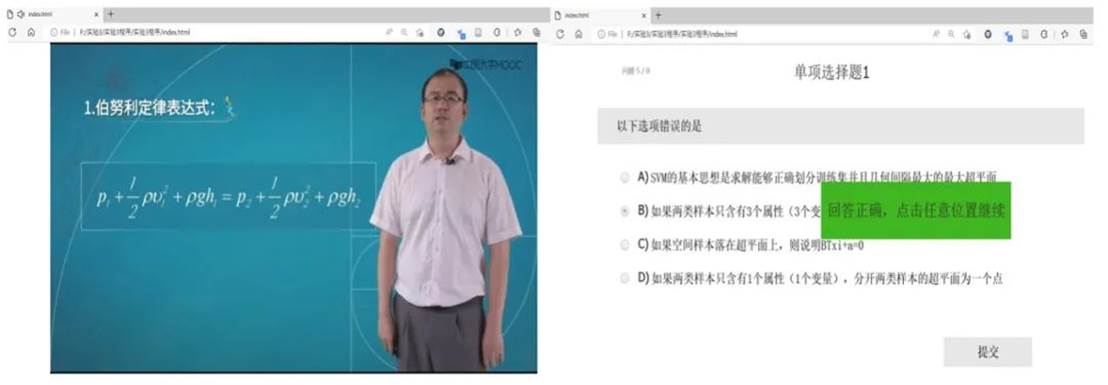
Fig. 1 Illustrationof the web interface for learning video and the associated quiz
本实验采用被试内设计,即每个被试要观看所有3个视频。每个视频观看后,学生需要评估视频学习时的流体验、感知到的任务要求、压力以及享乐水平。整个实验过程,我们通过生理多导仪采集被试的ECG信号,通过Kinect体感摄像头采集上半身关节点信号,通过GUCEE HD98 高清摄像头采集面部表情,通过数字录音笔采集语音信号。具体的实验过程见图2。
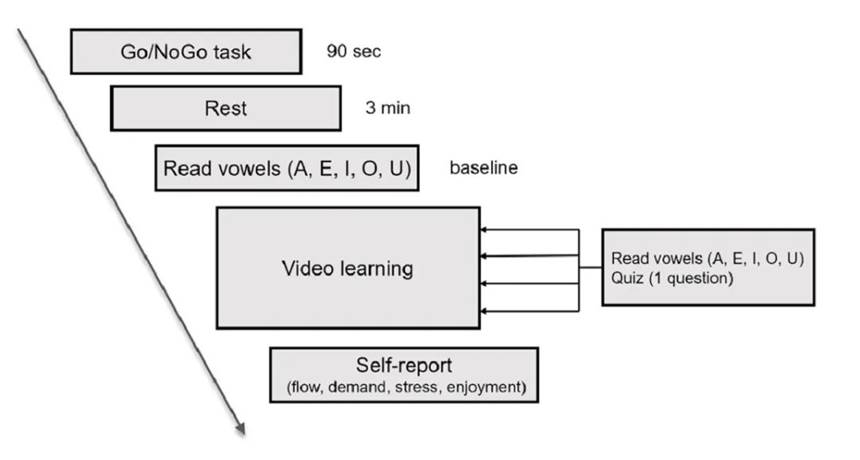
Fig. 2 Schematic diagram of the experimental procedure in each video learning session
数据分析
首先,必须确保被试学习状态的操纵是成功的。因此需要筛选一些被试,保证每个被试的主观评估要满足3个标准。无聊条件下感知到的任务要求和压力均低于流体验和焦虑条件;流状态下感知到的享乐水平和流体验分数均高于无聊和焦虑条件;同时,焦虑条件下感知到的任务要求和压力均高于流体验和焦虑条件。最终27个被试纳入接下来的分析。
其次,对每个视频最后5分钟所对应的4种模态数据进行预处理并进行特征提取。数据预处理方式根据学习状态识别和流体验预测分别进行。具体的预处理过程见图3。
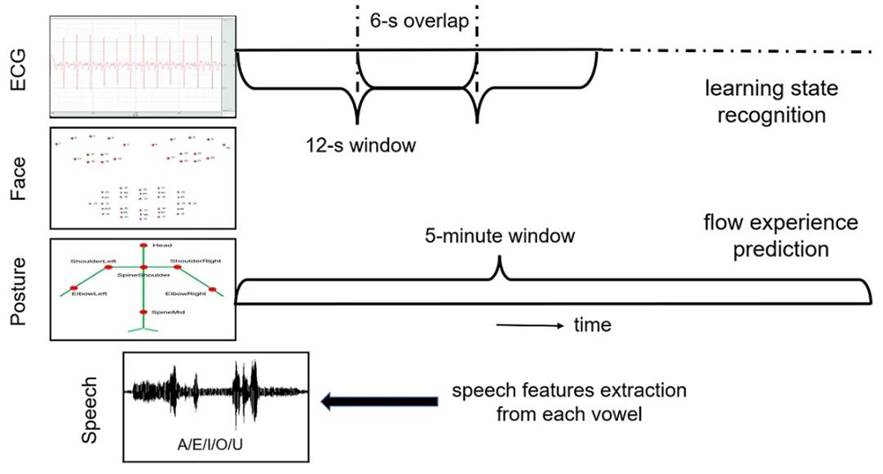
Fig. 3 The data preprocessing process in the last 5 minutes of each video learning process
然后,从4个模态信号中提取了共291个特征。生理特征包括心率、心率变异性等10个;姿态和面部表情都包含空间类特征(如关节点距离)和时序性特征(如关节点速度),具体见图4,语音特征包括MFCC等58个。所有数据减去基线(除姿态数据)并做了归一化处理。
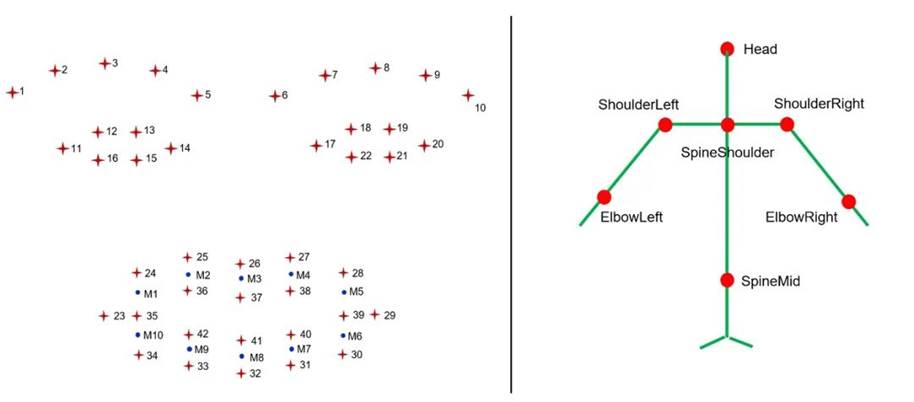
Fig. 4 Forty-two facial landmarks (left panel; the blue landmarks refer to the midpoints of the upper and lower red landmarks recognized on the lips) and 7 upper body joint points (right panel)
我们在分类建模和回归建模之前使用广义加性模型(GAMs)进行了监督特征选择。通过GAMs,我们获得了特征重要性排名,并从每种模态的数据中选择了重要特征。之后,将选择的特征纳入随机森林和MLP神经网络模型。我们还采用了留一被试交叉验证及多模态决策融合,见图5。
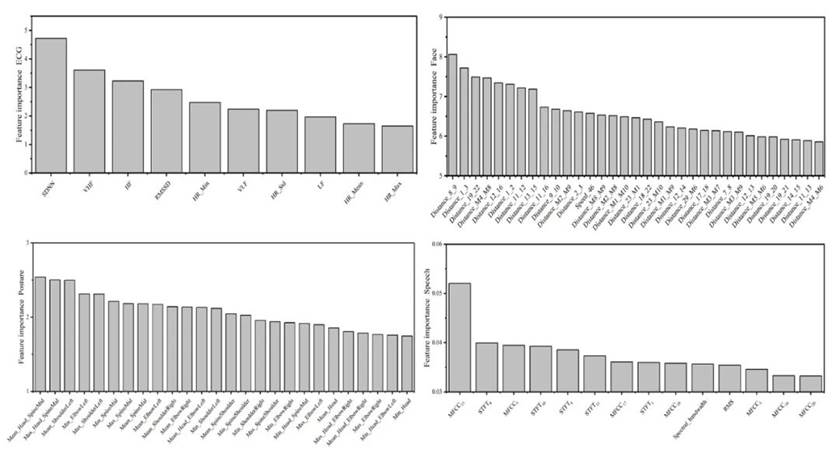
Fig. 5 Schematic illustration of the decision-level fusion of multimodal data
操作检验结果
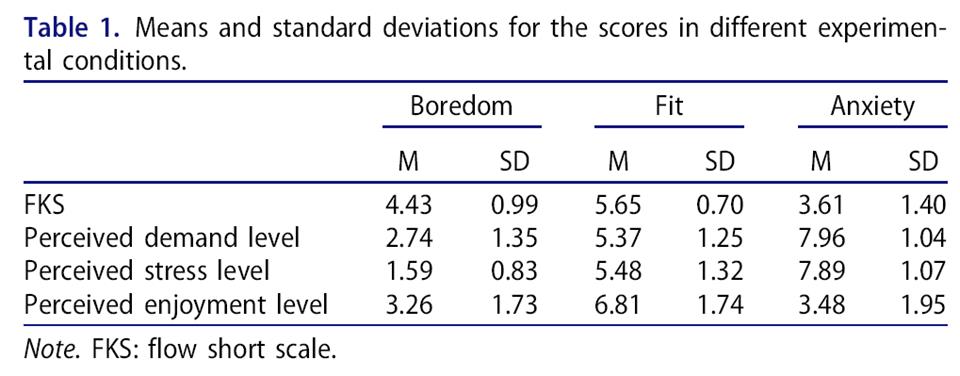
27名被试的流体验分数和感知要求/压力/享乐水平见表1,经检验,我们认为三个视频的学习过程是能够成功地促发学生的无聊感、流状态和焦虑感。
学习状态识别的特征选择
在分类建模前,使用逻辑GAMs选择了每个模态重要的特征并获得重要性排名,见图6。我们还探索了每个模态TOP3特征在3个学习状态下的差异,见表2。
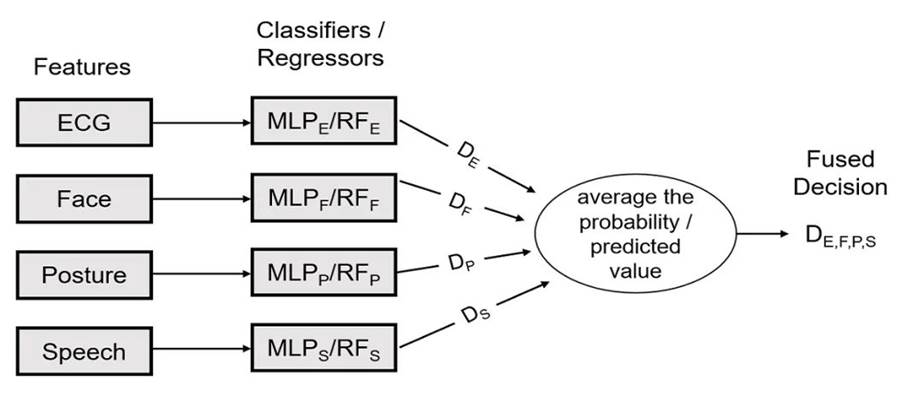
Fig. 6 The importance ranks of selected features for learning state recognition
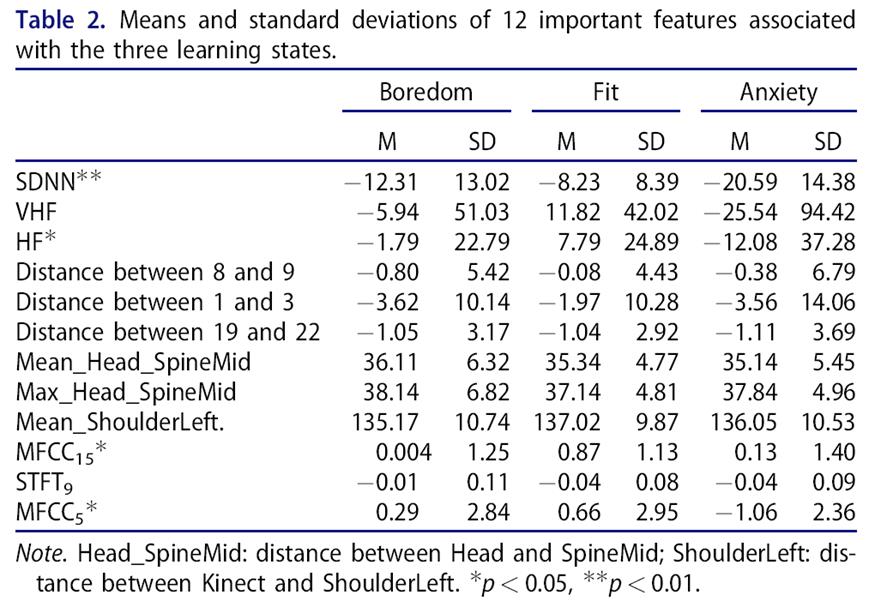
结果发现,SDNN, HF, MFCC15和MFCC5这四个特征的变化表现出相同的趋势,随着视频难度的增加,它们的值先增加后减少,在流状态下达到了最高水平,见图7。
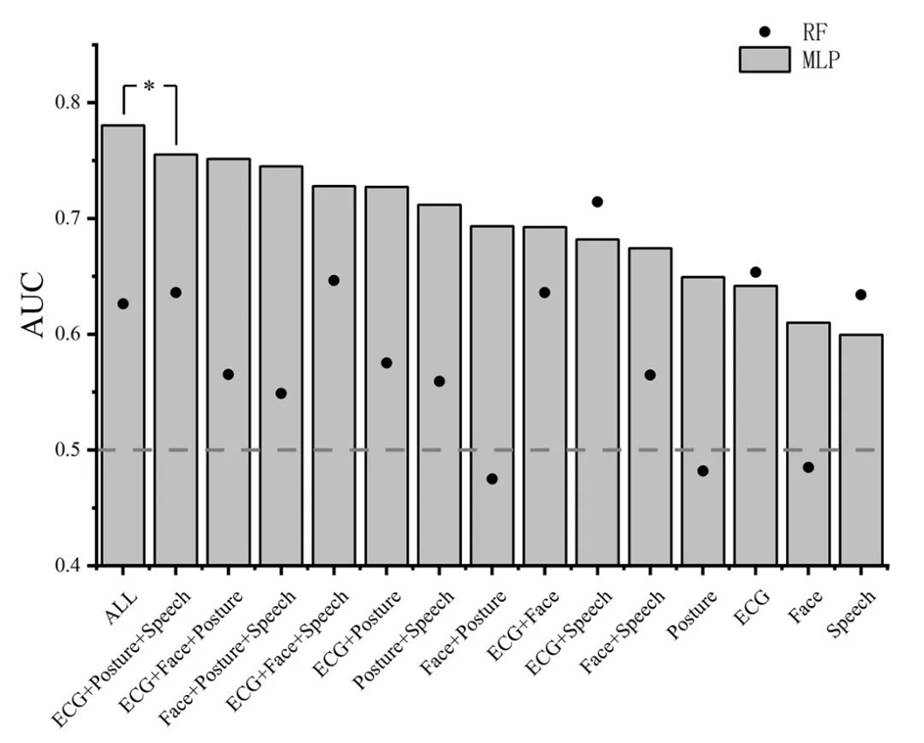
Fig. 7 The differences in SDNN, HF, MFCC15 and MFCC5between the three learning conditions (i.e., boredom, fit, anxiety). The error bars represent the 95% confidence interval. *p < 0.05, **p < 0.01.
分类建模
使用AUC作为分类的绩效指标,结果见图8。我们发现最佳模型(ALL:4种模态的融合)的绩效比其他任何一种融合结果都显著的好。
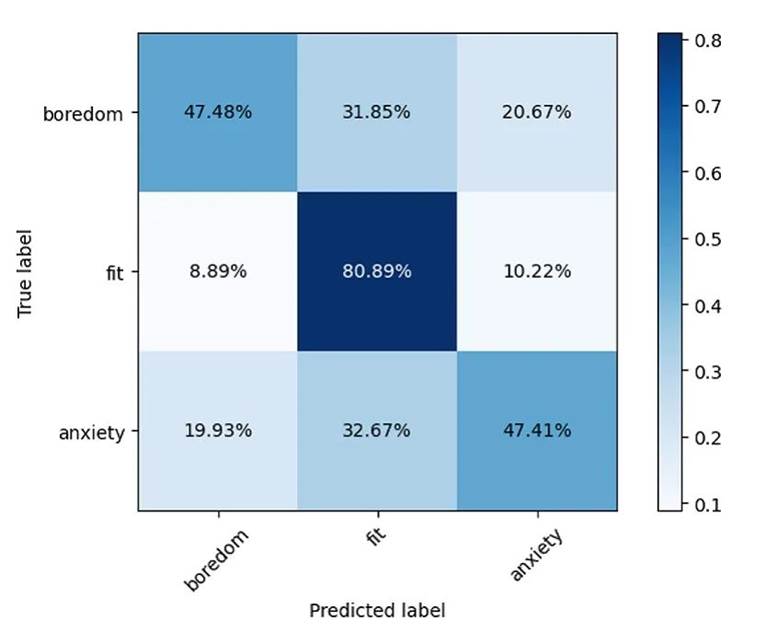
Fig. 8 Mean AUC of MLP and RF classifiers with different modality fusion
图9展示了最佳模型的混淆矩阵。
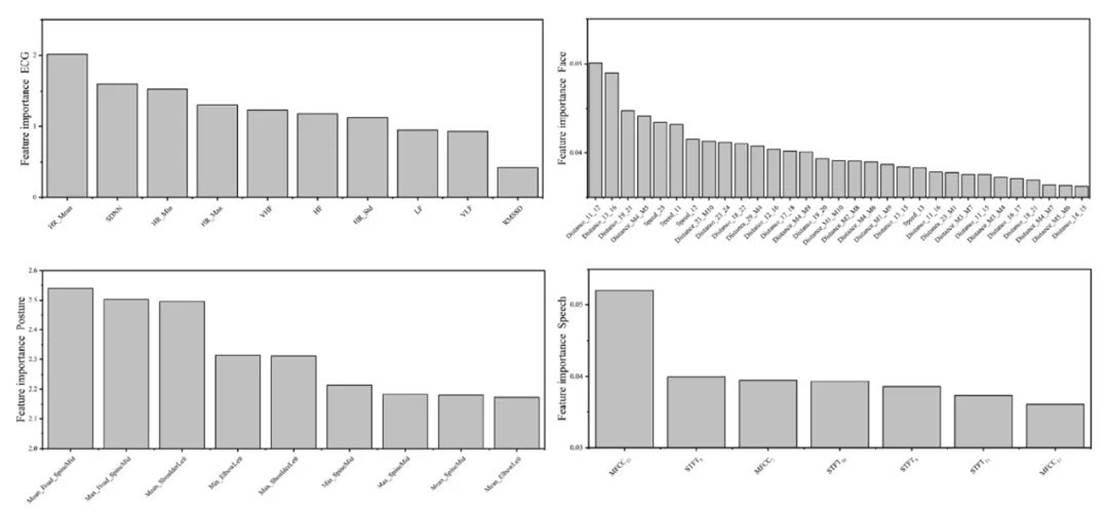
Fig. 9 Confusion matrix of the optimal classification model using all selected important features
流体验预测的特征选择
在回归建模前,使用线性GAMs选择了每个模态重要的特征并获得重要性排名,见图10。
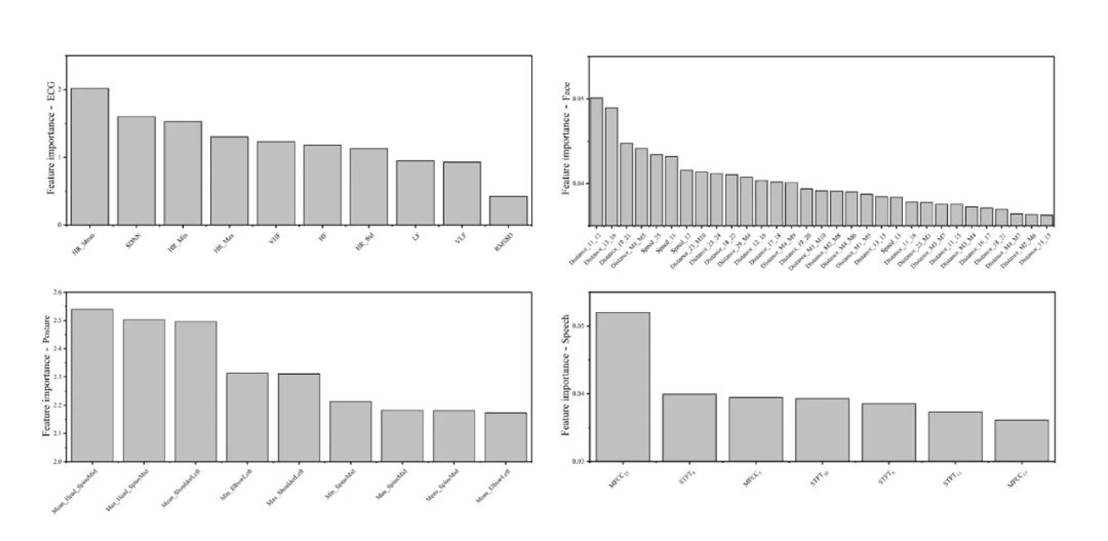
Fig. 10 The importance ranks of selected features for flow experience prediction
回归建模
我们用RMSE作为回归的绩效指标,结果见图11。结果发现基于心电和姿态两模态融合的MLP回归器给出了最佳的心流体验预测。然而,只需利用单个模态(心电)的信息,模型就可以有效地减少预测误差。
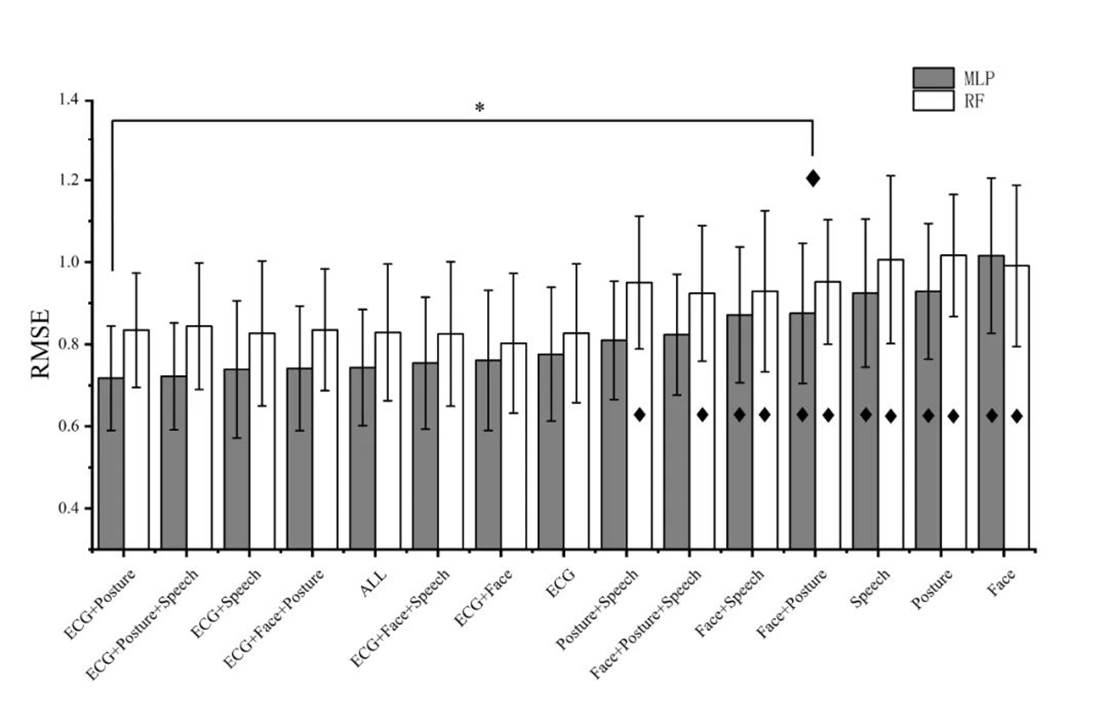
Fig. 11 Mean RMSE of MLP and RF regressors with different modality fusion. ¨ represents the regression models that performed significantly worse than the optimal prediction model (i.e., MLP of 'ECG+Posture'). The error bars represent the 95% confidence interval. *all ps< 0.05.
综上所述,我们在心流理论框架下模拟了一个在线视频学习场景,并使用四种传感器收集学生的生理、面部、姿势和语音数据,来识别不同的学习状态并预测他们的心流体验。本研究提出了一种结合多模态数据提高学习状态识别准确度的有效方法。
参考文献
Yankai Wang, Bing Chen, Hongyan Liu* & Zhiguo Hu* (2023): Understanding Flow Experience in Video Learning by Multimodal Data. International Journal of Human–Computer Interaction.
DOI: 10.1080/10447318.2023.2181878